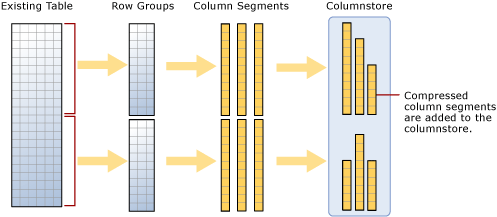
First of all, defining the terms, a row store table or index is a classical table without any index (heap) or with a CI (clustered index) in a row store format. This was not regularly mentioned or discussed, because it was the only way for years…(decades…). Except starting with SQL Server 2014 it was the first introduced a new data store format: “the CCI – clustered columnstore index (in SQL 2012 it was read-only, so nonclustered columnstore index-NCCI). Therefore, the columnstore index is a new type of “index” (or table storage) that stores data in a columnar format.
A good use of a clustered columnstore index is in data warehouse workloads, because it improves query performance up to 10 times, ss well as that it reduces the physical storage cost (a classical table occupying 50 GB of storage with columnstore index would be around 5-7 GB). The columnstore data format is a highly compressed data format that has several benefits from the analytical standpoint.
Benefits:
- faster (analytical) queries (faster table joins and group by-type of queries)
- (new) batch execution mode (a.k.a. vectorized execution)
- reduces physical I/O (when querying only some – not all – table’s columns)
- smaller memory footprint (because of data compression)
Not to use for:
- operational workloads (lots of small no. of rows to insert – trickle insert)
- large updates, or delete (instead truncate and bulk insert) – large meaning in % of total table rows
Table Partitioning
So for smaller tables, say up to 50-150 million of rows (mostly depending on the number of columns, also on hardware you have available) you can just create a columnstore index from a heap table or a clustered index table (with the drop_existing hint). In having larger tables you might want to consider using table (index) partitioning. Partitioning means just slicing the large table in more manageable parts – still using the columnstore index (compression). We dive into code in the next lines, respectively. Examples work in the WideWorldImporters sample database.
Code for creating a columnstore index (on a heap/unindexed table):
CREATE CLUSTERED COLUMNSTORE INDEX [CCI_Order] ON [Fact].[Order] WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0)
If you already have a clustered index on the table, you just change the drop_existing hint to on.
CREATE CLUSTERED COLUMNSTORE INDEX [CCI_Order] ON [Fact].[Order] WITH (DROP_EXISTING = ON, COMPRESSION_DELAY = 0)
Code for creating a partitioned columnstore index:
CREATE PARTITION FUNCTION [pf_OrderDate](date) AS RANGE LEFT FOR VALUES (N'2013-12-31', N'2014-12-31', N'2015-12-31', N'2016-12-31', N'2017-12-31'); CREATE PARTITION SCHEME [ps_OrderDate] AS PARTITION [pf_OrderDate] TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY] ,[PRIMARY]); select top 0 * into [Fact].[Order_CCI_part] from [Fact].[Order]; CREATE CLUSTERED COLUMNSTORE INDEX [CCI_Order_part] ON [Fact].[Order_CCI_part] WITH (DROP_EXISTING = off, COMPRESSION_DELAY = 0) on [ps_OrderDate]([Order Date Key]);
Msg 35316, Level 16, State 1, Line 21
The statement failed because a columnstore index must be partition-aligned with the base table. Create the columnstore index using the same partition function and same (or equivalent) partition scheme as the base table. If the base table is not partitioned, create a nonpartitioned columnstore index.
Oh, wow… partition-aligned…soo, what? – was also my reaction when I was first confornted with the error. But, when you understand what SQL Server is trying to do, or just how to tell it what you want it to do is not that hard.
We solve the partition alignment problem by creating a clustered index on the same partititioning function and then create a clustered columnstore index with the drop_existing hint on. Let’s do it.
CREATE PARTITION FUNCTION [pf_OrderDate](date) AS RANGE LEFT FOR VALUES (N'2013-12-31', N'2014-12-31', N'2015-12-31', N'2016-12-31', N'2017-12-31'); CREATE PARTITION SCHEME [ps_OrderDate] AS PARTITION [pf_OrderDate] TO ([PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY], [PRIMARY] ,[PRIMARY]); select top 0 * into [Fact].[Order_CCI_part] from [Fact].[Order]; CREATE CLUSTERED INDEX [CCI_Order_part] ON [Fact].[Order_CCI_part] ( [Order Date Key] )WITH (SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [ps_OrderDate]([Order Date Key]) CREATE CLUSTERED COLUMNSTORE INDEX [CCI_Order_part] ON [Fact].[Order_CCI_part] WITH (DROP_EXISTING = ON, COMPRESSION_DELAY = 0)
This code will now work. The difference is in the creation of a clustered index so as to align partitions and then on top create the columnstore index.
Inserting data
When inserting lots of data (over 100.000 rows or over 1.000.000 rows) you should always bulk insert which is quite straightforward to do (just use tablock hint). This means the engine will automatically compress data (may be CPU instensive) before writing data to the disk – this is what you want. This i sthe faster way. The other way inserting without the tablock hint triggers the old “row by row” insertion which is bad for inserting in the columstore index, because it will go in two steps, first, classical insertion and when it reaches some treshold (100.000 rows), and only then the compression process will be triggered reading the rows in memory, applying the compression and writing data to the disk. Hence, you’d be doing writing 2 times to the disk.
Inserting in a columnstore index:
INSERT INTO [WideWorldImportersDW].[Fact].[Order_CCI] WITH(TABLOCK) SELECT [Order Key] ,[City Key] ,[Customer Key] ,[Stock Item Key] ,[Order Date Key] ,[Picked Date Key] ,[Salesperson Key] ,[Picker Key] ,[WWI Order ID] ,[WWI Backorder ID] ,[Description] ,[Package] ,[Quantity] ,[Unit Price] ,[Tax Rate] ,[Total Excluding Tax] ,[Tax Amount] ,[Total Including Tax] ,[Lineage Key] FROM [WideWorldImportersDW].[Fact].[Order]
The important part is the tablock hint, so as to bypass the sequential write and to write directly in columstore format (applying data compression) – this way the operation is much faster.
Inserting in a partitioned columnstore index:
So for insertion into a partitioned table (hence: also with columnstore compression) is not just trivial. It includes a couple of steps to make it enterprise grade acceptable. These include at least these:
- Insert part of data (same partition data) in a work non-partitioned table (that has CCI applied)
- Call the Switch partition statement – switch the work table to a partition from the partitioned table
- Clean the work table and do it all over again for all the data (partitions)
There are some technical details (creating constraints and dropping them) that go as part of the main step, but all in all, these three steps are crucial to a partitioned insert in a manageable and quick way.
declare @currDate varchar(10) = '2013-12-31' declare @currDate_next varchar(10) declare @maxYear varchar(10) = (select convert(date,DATEADD(yy, DATEDIFF(yy, 0, GETDATE()), 0))) declare @msg varchar(max), @SQLStmt nvarchar(max) declare @debug bit = 1 SET ANSI_WARNINGS OFF while convert(date,@currDate) < convert(date,@maxYear) begin set @currDate_next = convert(varchar,dateadd(year, +1, convert(date,@currDate))) set @msg = 'Current: ' + @currDate + ', maxYear: ' + @maxYear set @msg = @msg + char(13) + char(10) + 'Date condition: dateCol > ' + @currDate + ' and dateCol <= ' + @currDate_next RAISERROR(@msg, 0, 1) WITH NOWAIT if (select count(*) from [Fact].[Order_CCI_switch]) != 0 begin RAISERROR('The work/switch table is not empty!', 0, 10) break end -- clean variables set @SQLStmt = '' set @SQLStmt = ' alter table [Fact].[Order_CCI_switch] drop constraint if exists OrderDateCheck; ' print @SQLStmt if @debug = 0 exec sp_executesql @SQLStmt set @SQLStmt = ' insert into [Fact].[Order_CCI_switch] with(tablock) select * from [Fact].[Order] where [Order Date Key] > ''' + @currDate + ''' and [Order Date Key] <= ''' + @currDate_next + '''' print @SQLStmt if @debug = 0 exec sp_executesql @SQLStmt set @SQLStmt = ' alter table [Fact].[Order_CCI_switch] add constraint OrderDateCheck check ([Order Date Key] > convert(date,''' + @currDate + ''') and [Order Date Key] <= convert(date,''' + @currDate_next + ''') and [Order Date Key] is not null) ' print @SQLStmt if @debug = 0 exec sp_executesql @SQLStmt --select $partition.[pf_OrderDate](convert(varchar,@currDate)) --select min(daT_knj), max(dat_knj) from [RP_PROMET_ALL_YEAR_CCI_work] set @SQLStmt = ' alter table [Fact].[Order_CCI_switch] switch to [Fact].[Order_CCI_part] partition ' + convert(varchar, $partition.[pf_OrderDate](@currDate_next)) + ' ' print @SQLStmt if @debug = 0 exec sp_executesql @SQLStmt set @currDate = dateadd(year, 1, convert(date,@currDate)) end
Hope this overview gets you started in giving legacy databases a new shine, saving disk space and improving query speed!

Leave a comment